在大模型迈向“更大、更长、更快”的时代,阿里云通义团队于 2025 年 9 月发布了下一代基础模型架构 Qwen3-Next。该架构以“极致效率优化”为核心目标,通过混合注意力机制、高稀疏度 MoE、训练稳定性保障和推理性能优化四大支柱,实现了在参数规模、上下文长度与推理成本之间的精妙平衡。
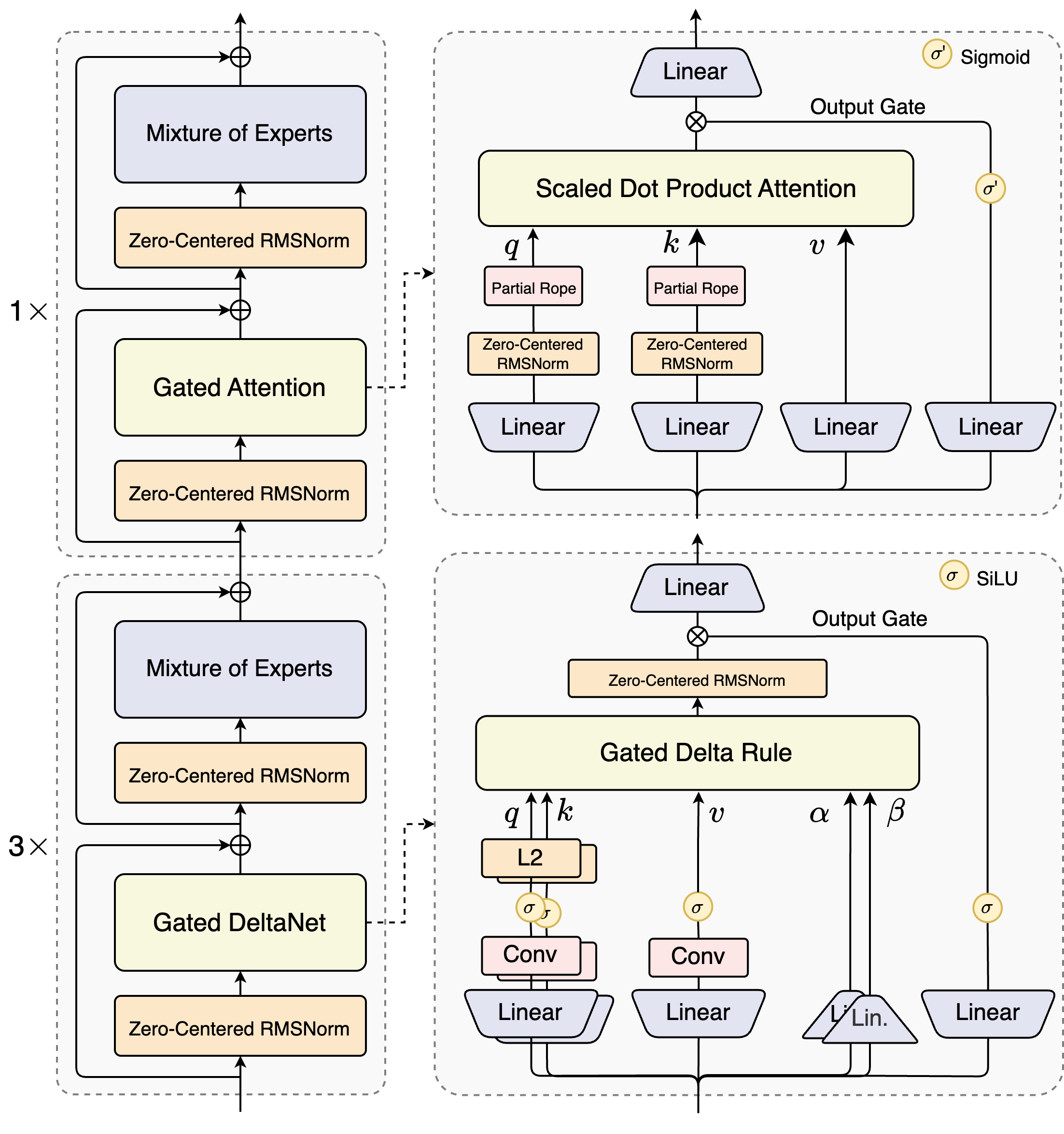
混合注意力架构:Gated DeltaNet 与 Gated Attention
Qwen3-Next 的核心创新之一是其 混合注意力(Hybrid Attention)机制,在一个典型的模型 block 中,采用 3 层 Gated DeltaNet + 1 层 Gated Attention 的布局,即 75% 的线性注意力与 25% 的标准注意力混合。
Gated DeltaNet:线性复杂度
Gated DeltaNet 是一种基于状态空间模型(SSM)的线性注意力变体,源自 NVIDIA 的《Gated Delta Networks: Improving Mamba2 with Delta Rule》。
这种机制实现了 接近 $O(N)$ 的时间和内存复杂度,在长达 20,000 token 的序列上仍保持低困惑度。
Gated Attention
在 Qwen3-Next-80B 中,Gated Attention 采用 分组查询注意力(GQA),配置为:
- 查询头(Q heads):16
- 键值头(KV heads):2
- 每头维度:256
GQA 通过减少 KV 头数量,大幅降低 KV Cache 内存占用,同时保留多头表达能力。该层被置于每 4 层 block 的末尾,用于整合 Gated DeltaNet 提取的长程特征,并进行局部融合。
动态融合机制
两种注意力通过一个 门控融合单元(Gating Mechanism) 动态分配信息流。
高稀疏度 MoE:激活比高达 1:50 的极致稀疏
Qwen3-Next-80B-A3B 模型总参数达 800 亿,但 每个 token 仅激活约 30–39 亿参数,激活比高达 1:26.7 至 1:50,远优于稠密模型(如 Qwen3-32B 的 1:1)。
MoE 结构设计
| MoE 参数 | Qwen3-Next (80B) | DeepSeek MoE | Mixtral 8x7B |
|---|---|---|---|
| 总专家数 | 512 | Varies by version (e.g., 256 in V3) | 256 (in some implementations) |
| 路由专家数 | 10 | 160 (in V2) | 128 |
| 共享专家数 | 1 | 2 (in V2) | 1 |
| 激活专家数 (K) | Top-K (10 selected + 1 shared) | 6 (in V2) | Typically 2 |
| 辅助损失 | Yes (router_aux_loss_coef=1e-3) |
Yes (various losses) | Yes |
- 总专家数:512
- 路由专家数:10(Top-K 选择)
- 共享专家数:1(始终激活)
每个 token 的激活路径为:
\(\text{Activated Experts} = \text{TopK}(10) + \text{Shared Expert}\)
共享专家作为“稳定器”,防止路由偏差导致的信息丢失,提升训练鲁棒性。
Infra
- 负载均衡:引入路由器辅助损失(
router_aux_loss_coef=1e-3),鼓励均匀激活。 - 跨 GPU 通信:高稀疏性导致通信模式随机,需拓扑感知调度(如 FasterMoE)或块稀疏矩阵乘(如 Megablocks)。
- 动态批处理:在线服务中需实时监控专家负载,结合连续批处理(Continuous Batching)优化资源利用率。
训练稳定性优化:从 Zero-Centered RMSNorm 到路由器初始化
大规模 MoE 模型易出现梯度爆炸或“专家死亡”问题。Qwen3-Next 通过以下策略保障训练稳定:
Zero-Centered RMSNorm
传统 RMSNorm 输出可能偏移,而 Zero-Centered RMSNorm 通过特殊权重设置,使输出 统计上零中心化:
\[\hat{x}_i = \frac{x_i}{\sqrt{\mathbb{E}[x^2] + \epsilon}}, \quad \text{with } \mathbb{E}[\hat{x}] \approx 0\]该设计抑制激活值无界增长,并减少专家输出差异,利于路由均衡。
路由器归一化初始化
在训练初期,对路由器参数进行归一化,确保所有专家初始激活概率均衡,避免“专家死亡”,为公平竞争提供起点。
推理性能优化:KV Cache、长上下文与推测采样
Qwen3-Next 从架构层面优化推理全流程:
KV Cache 优化
- Prefill 阶段:75% 的 Gated DeltaNet 无需存储 $N \times N$ 注意力矩阵,显著降低内存压力。
- Generation 阶段:GQA 仅缓存 2 个 KV 头,KV Cache 内存减少约 8 倍。
实测显示,在 32k+ 上下文下,Prefill吞吐量达 Qwen3-32B 的 10 倍以上,Generation速度提升近 4 倍。
超长上下文支持
- 原生支持:262,144 token(256K)
- 扩展支持:通过 YaRN(Yet another RoPE extension) 可扩展至 1M token
位置编码仍采用 RoPE,因其良好的相对位置建模能力与 KV Cache 兼容性。
推测采样(Speculative Decoding)
Qwen3-Next 原生集成 MTP 机制,支持推测采样:
- 草稿模型并行预测多个 token
- 主模型批量验证,将串行解码转为并行验证
可通过 --speculative-num-steps 3 启用,显著提升编程等高预测性任务的吞吐量。
本文基于阿里云通义团队公开技术文档整理。