CPU & GPU
计算机的基本组成结构
计算机的基本组成单元(冯诺依曼结构):
- 存储器
- 控制单元
- 算数逻辑单元
- 输入输出
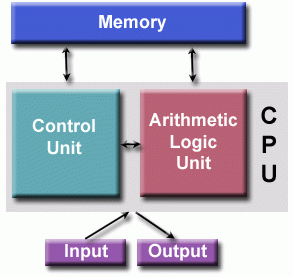
读写:由RAM(Random Access Memory)存储指令和数据;
控制单元:读取指令/数据,解码指令并串行地执行;
算数逻辑单元:基本的运算单元;
输入/输出:人机交互的输入输出接口。
What is CPU?
CPU(Central Processing Unit)是计算机系统的重要组成部分,经常被比喻为计算机的“大脑”。CPU的主要职责是执行位于存储器(Memory)中的指令(Instructions),进行算数、逻辑运算,并管理计算机中不同不同部分之间的数据交换。
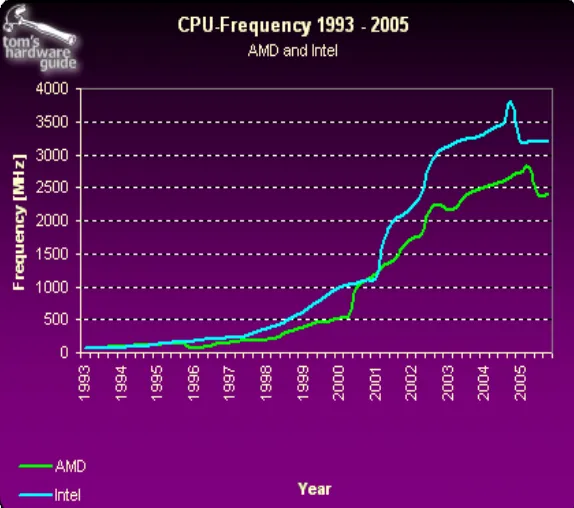
CPU的性能瓶颈
CPU的性能评价指标经常是时钟频率(Clock speed),表示CPU每秒可以执行的指令数;以及核心数(number of cores),表示CPU包含几个独立的计算单元。
 |
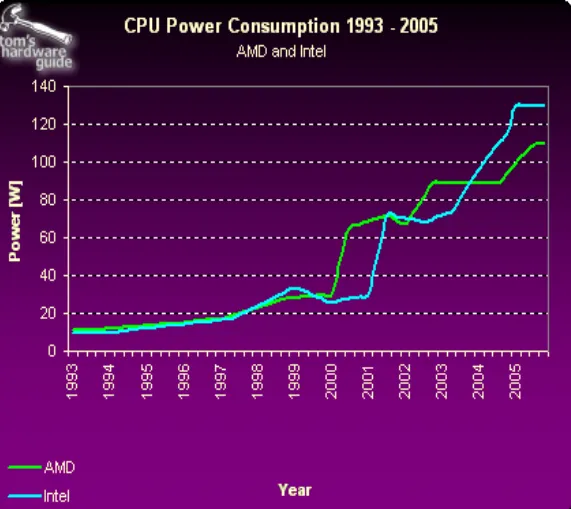 |
早期CPU的发展以提高时钟频率为主,但这种趋势在2004~2005年就得以减缓,主要原因是由功耗限制Power Wall和访存限制Memory wall两大阻碍。
CPU的时钟频率的提高也同时带来了更大的功耗,意味着需要更大的电源,以及可能面临的运行时高温度问题。另一方面,受限于存储技术的发展限制,在很长一段时间内计算机程序的主要性能瓶颈并不在计算上,而是在访存上。
因此,CPU从不断的提高时钟频率转而向提高核心数的方向发展,例如现在常见的都是4核、8核CPU。CPU核心更擅长于串行任务的计算。
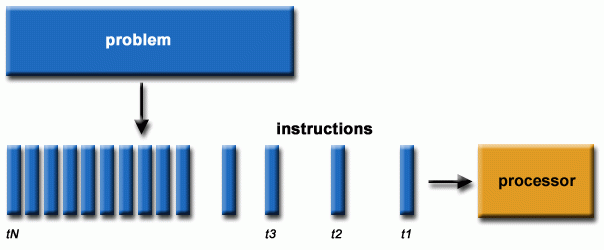
What is GPU?
GPU (Graphics Processing Units,图形处理单元,也称为显卡) ,从命名可能看出来最早是为了加速图形处理(特别是电子游戏)而设计的,后来也被广泛运用于其他并行计算领域。
与CPU的设计理念不同,GPU主要被设计用于处理数以千计的重复性任务。以图形处理为例,可以把显示器中的每个像素点的计算看成是一个任务,每个像素点之间相对独立互不干扰。GPU可以高效的并行处理每个像素点运算。
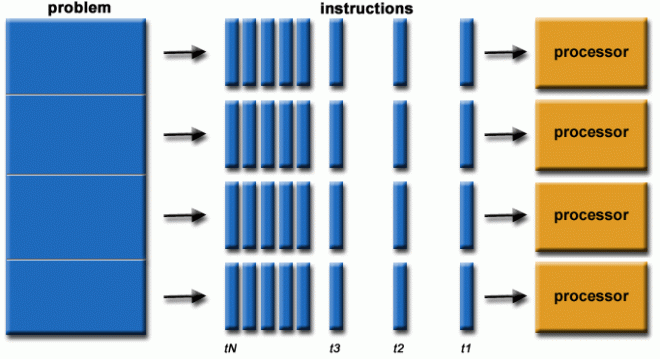
GPU的特性以及优势
GPU(Throughput-Oriented Design)相较于CPU(Latency-Oriented Design)的最显著的优势就是拥有更高的峰值访存与计算性能。如果能利用这一特性,可以在GPU上开发运行某些应用时可以较CPU带来显著的性能提升。例如:生成式AI、数字信号处理、视频图像处理、生物信息学、网络信息搜索、气象预报、加密系统等领域。
造成GPU与CPU的峰值访存与计算性能差距的最主要原因是两者的设计理念区别,它们被设计用于处理不同类型的任务。
CPU被设计得更擅长处理复杂的任务序列,一个程序也可能包含数十个线程(Threads)的并行。其中每个线程可能运行于不同的核心(Cores)上,CPU的每个核心都很强大,因此每个线程的任务相对复杂。
而GPU是被设计用于并行处理成千上万个任务的,GPU处理每个任务的核心相较CPU更弱,但胜在数量。
从下图可以看到,GPU芯片的更多晶体管都用于数据处理核心;而CPU则有更多的晶体管用于缓存(Cache)和控制单元(Control unit)。
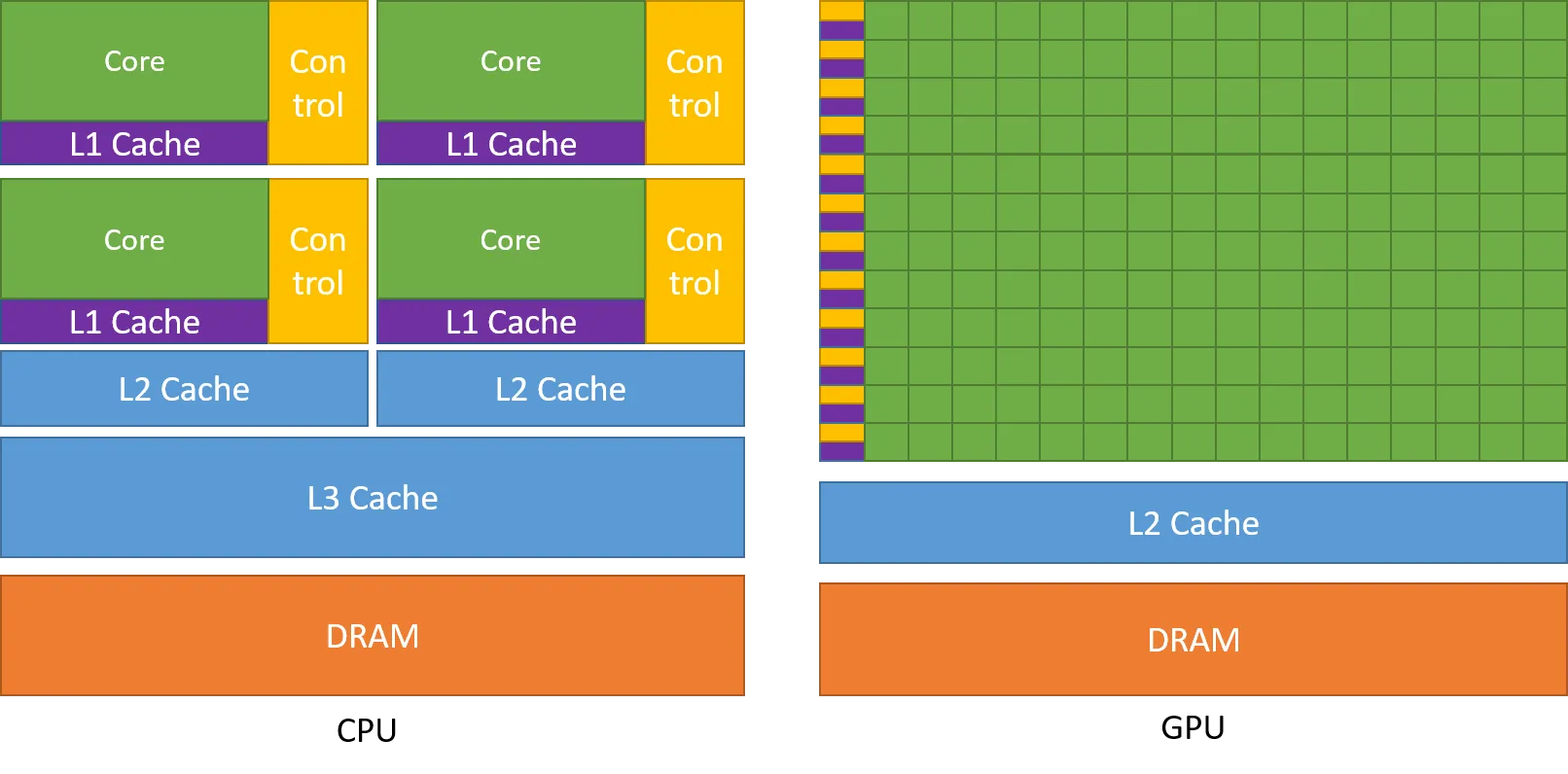
使用更多的晶体管用于数据处理核心(例如浮点数计算单元)也就带来了更高的浮点计算性能(FLOPs, floating-point operations per second)。
另一方面,GPU可以使用延迟隐藏(Latency hiding)等手段来降低访存带来的等待。
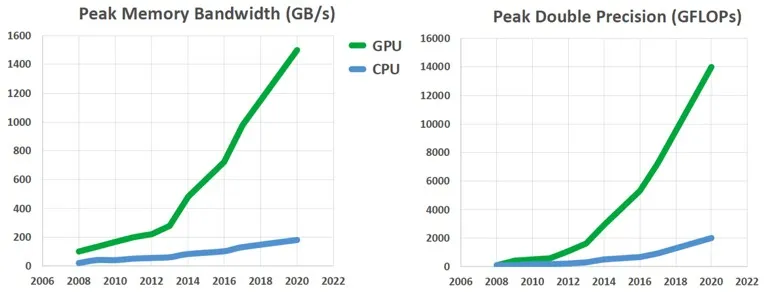
总的来说,通常的应用都是串行计算和并行计算的混合。因此计算机系统被设计为由CPU与GPU的组合来最大化性能表现。
Flynn矩阵
一种并行计算机的分类方法,根据指令流和数据流的不同状态来分类。指令流(Instruction stream)与数据流(Data stream)各自可以是单(Single)和多(Multiple)两种状态,因此可以形成一个2×2的矩阵。
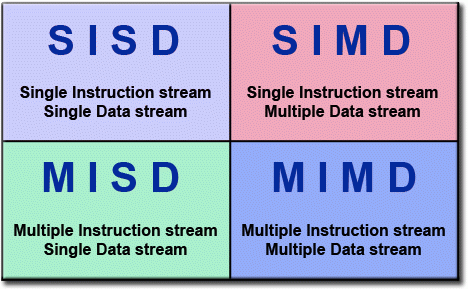
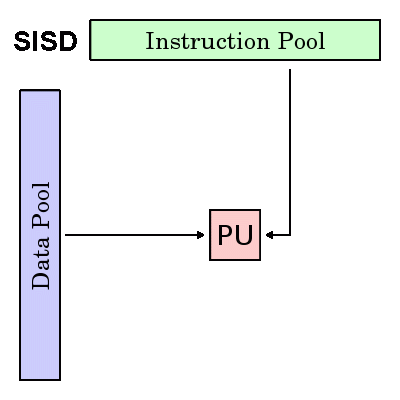
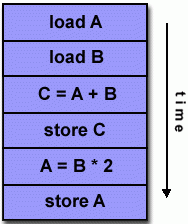
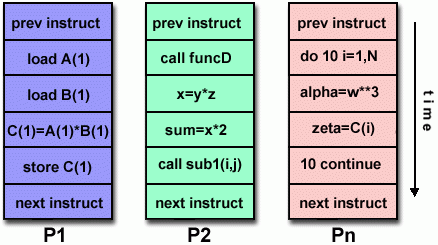
SISD:非并行计算机,一种古老的单核计算机架构:
 |
 |
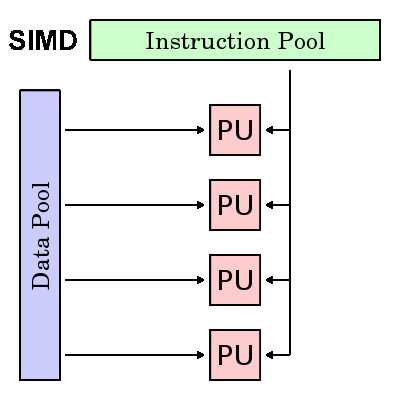
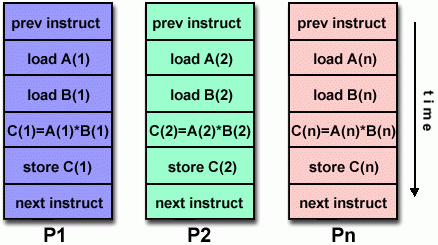
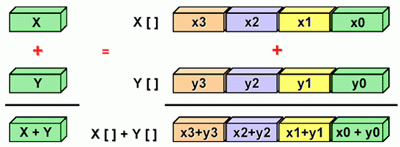
SIMD: 最适合用于处理任务之间具有高度相似规则的情形,例如图形处理器(GPUs):
 |
 |
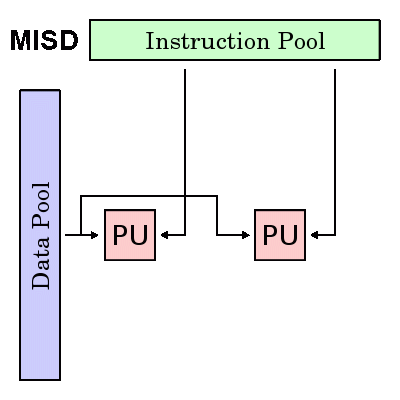
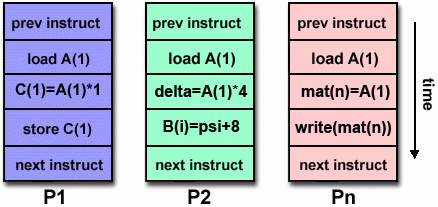
MISD:实际应用中较少见,一种理论上用途可能是对单个信号应用不同滤波函数:
 |
 |
MIMD:现代多核CPU的计算机最常见结构:
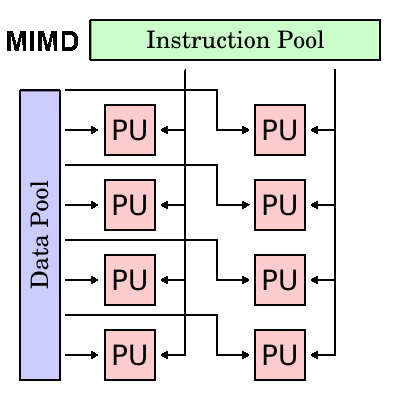 |
 |
Amdahl’s law
阿姆达定律指出了程序的加速比取决于程序中可以并行的部分(P)的占比:
\[\text{speedup} = \frac{1}{P/N+S}\]P = parallel fraction, N = number of processors and S = serial fraction.
speedup
-------------------------------------
N P = .50 P = .90 P = .95 P = .99
----- ------- ------- ------- -------
10 1.82 5.26 6.89 9.17
100 1.98 9.17 16.80 50.25
1,000 1.99 9.91 19.62 90.99
10,000 1.99 9.91 19.96 99.02
100,000 1.99 9.99 19.99 99.90
You can spend a lifetime getting 95% of your code to be parallel, and never achieve better than 20x speedup no matter how many processors you throw at it!
一个著名的quote:你可以用一辈子的时间来把代码的95%并行化,但是无论你加多少处理器,都不可能获得高于20x的加速比。
GPU计算单元结构
“学校模型”

在介绍GPU的物理结构和逻辑结构前,可以用一种直观的比喻来帮助理解,“学校模型”
例子:一个学校中有多个教室,每个教室中有多个学生。接下来,我们有若干个任务(具体数量可以根据情况有所不同)需要分配给学校的学生来处理。只不过需要遵循一定的规则:
- 每个教室最多只能处理1024个任务(每个班级最多只有1024个学生);
- 学生按照32个一组处理Task(线程按照Warps为单位进行调度)。
物理结构
http://users.umiacs.umd.edu/~ramani/cmsc828e_gpusci/lecture9.pdf
Let’s take Kepler or Fermi for example:
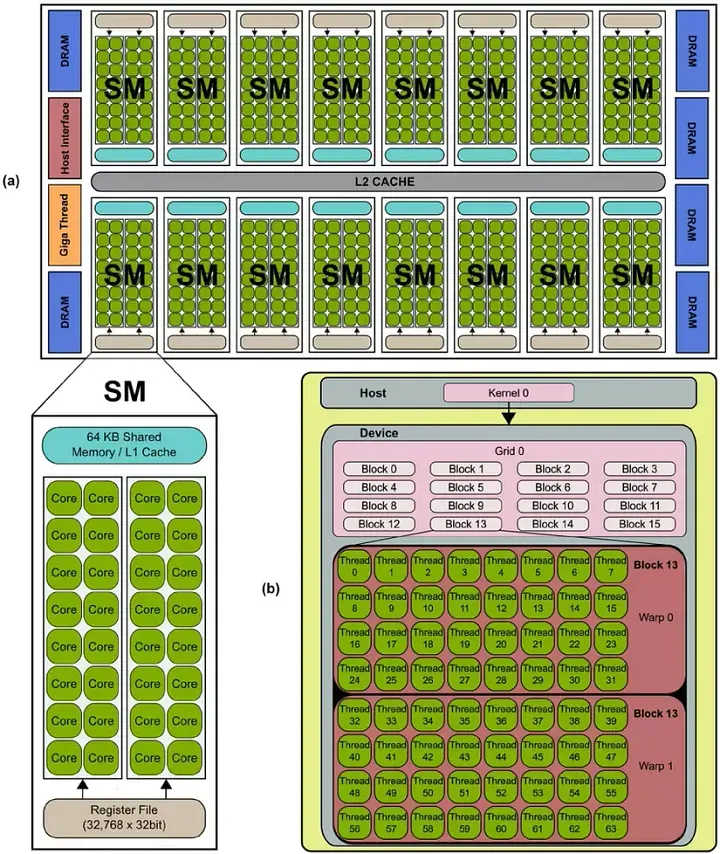
从上面的示意图可以看到,该GPU有十六个SMs,并且每个SM有32个Cores。
流处理器 Streaming Processors(SPs or cores):SPs是GPU中的主要处理单元,可以用于并行地在不同的数据上做计算。SP可以对应于“学校模型”中的课桌,每个SP都是用于处理一个个的任务。因此可以认为,有越多的SPs,就可以越多得并行处理任务。
流多处理器 Streaming Multiprocessor(SM or multiprocessor):SM是多个SP的组合。SM可以认为是“学校模型”中的教室。SM作为一个更高级别的SP集合,可以统一管理内部所有SP的任务处理调度。
具体到不同的GPU型号,SM和SP的数量各自不同。以Nvidia T4为例,T4总共有40个SMs,每个SM包含64个Streaming Processors。每个GPU的具体参数细节可以查阅Nvidia官方网站获得。

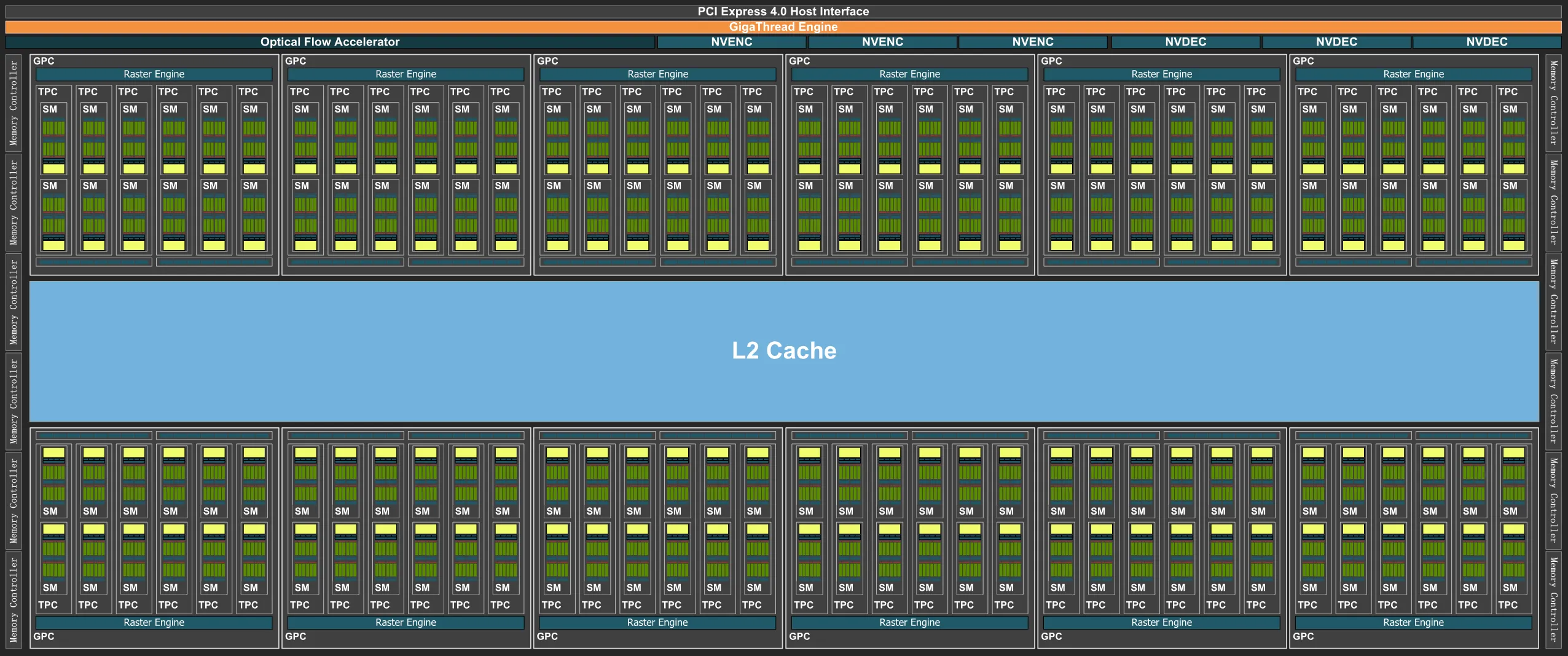
以Nvidia RTX4090为例,上图是一个SM的构成示例图,可以看到除了SPs(Cores or Processors),还包含几个其他的组成部分:
Caches: L1 Cache/Shared Memory、Texture cache等;
Schedulers for warps:以Warps为单独调度Threads。以“学校模型”为例,可以理解为将班级划分为若干个小组。每个小组由Scheduler for warps调度。
Registers:供Thread使用,提供最快的访存速度。
逻辑结构
https://en.wikipedia.org/wiki/Thread_block_(CUDA_programming>)
可以用下图来理解CUDA的编程结构:
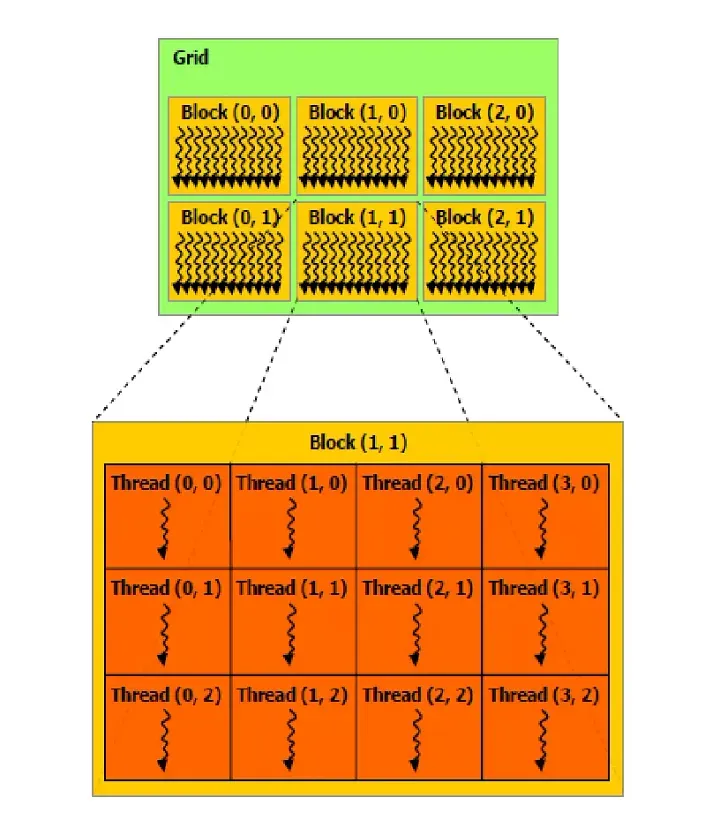
从上面的示意图可以看到此逻辑结构有2×3的6块blocks组成的grid,其中每个block由3×4个Threads组成。
Thread:一个任务的执行单元,每个Thread负责处理一个Task,可以对应于“学校模型”中的学生(苦力)。
Block:若干个Threads组成的集合,可以是一维、二维或者三维的排布。可以对应于“学校模型”中的班级。单个Block中的Threads数量存在上限,通常是最多可以包含1024个线程,Max dimension size of a thread block (x,y,z): (1024, 1024, 64). For example, a block with dimensions of (32,32,1) will have 1024 threads。
Grid:若干个Blocks组成的集合,可以是一维、二维或者三维的排布。可以对应于“学校模型”中的年级。Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)。
Warps:每个Block中的Thread将会被分为若干个Warps(对于CUDA编程者来说不可感知)。可以对应于“学校模型”中将班级划分为若干个小组。每个Warp包含连续的32个Threads,Warp内的32个线程执行相同的指令(Warp内的线程是同步的)。
https://slideplayer.com/slide/16690299/
关于Warp进阶阅读可以参考
https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/
问:以Nvidia G80为例。如果某个SM被分配了3个Thread Blocks,每个Block包含256个Threads,该SM中有多少个Warps?
答:每个Block被划分为 256/32 = 8 Warps。共有 8 * 3 = 24 Warps。在任意时刻,这24个Warps中只有一个Warp被Scheduler调度运行。
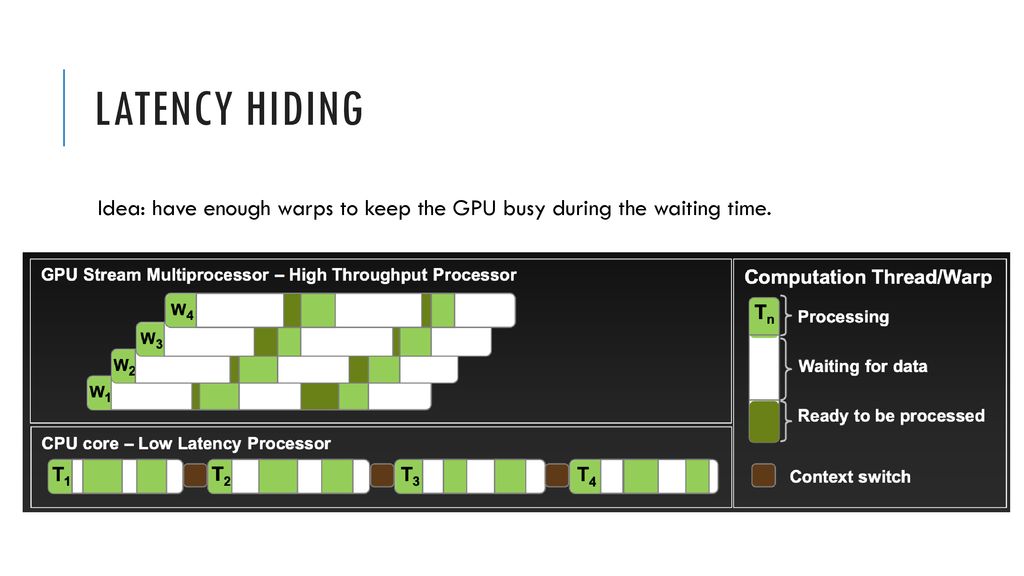
问:一个程序包含,1次对global memory的读操作(200 cycles)和4次独立的mutiply/add操作(每个4 cycles)。warps的context switch是零开销的,那么需要多少个warps才可以完全隐藏访存延迟?
答:每个warp有4个mutiply/add操作,4×4=16 个周期。我们需要覆盖200个周期,200/16=12.5,ceil(12.5)=13,至少需要13个warps可以完全隐藏访存延迟。
GPU的物理结构与逻辑结果之间存在对应关系:
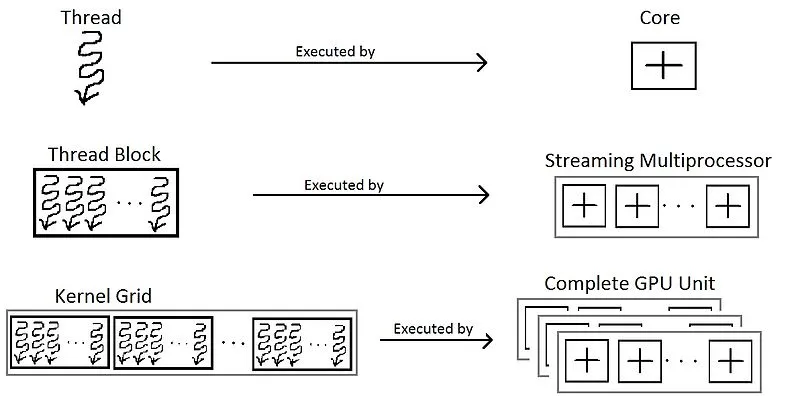
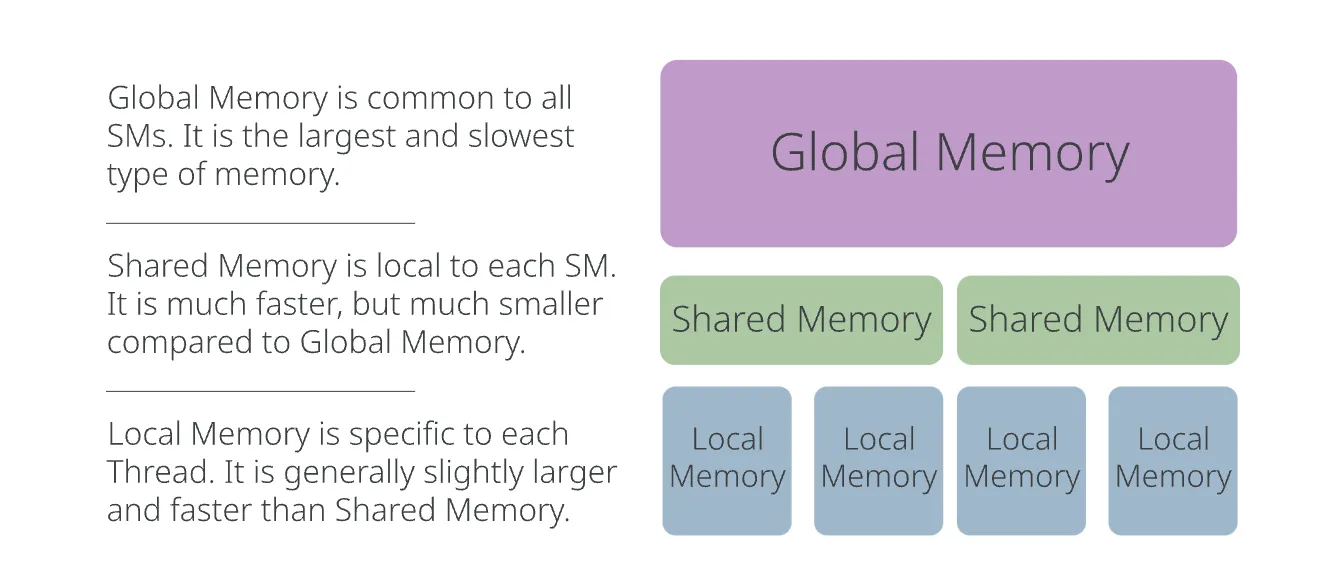
GPU的存储结构
GPU的逻辑存储结构
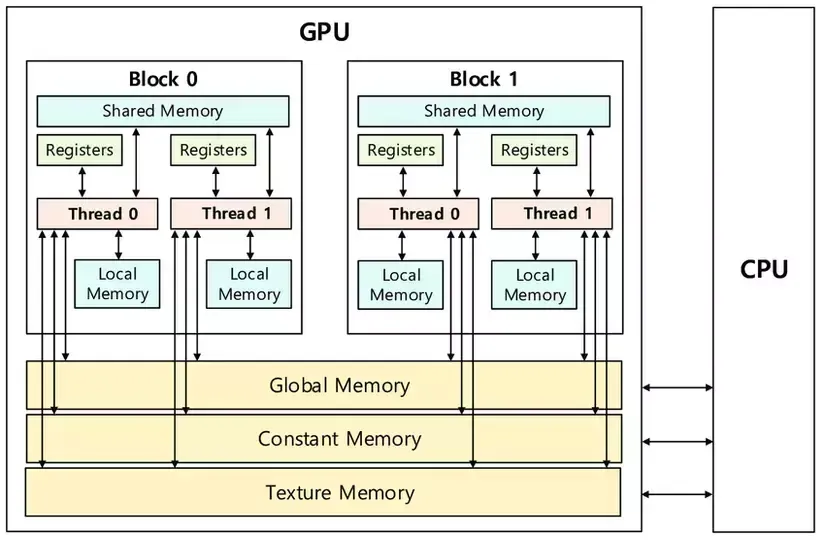
局部内存(Local Memory):每个线程可以使用其自己的局部内存,用于存储临时变量。具有最小的作用域,并且是专门为每个单独的线程分配的。“学校模型”中的课桌,每个学生可以访问自己的课桌。
共享内存(Shared Memory):同一线程块内的线程可以通过共享内存共享数据。这允许同一线程块内的线程之间更快地通信和访问数据,相比访问全局内存来说速度更快。“学校模型”中的讲台,每个班级都有一个讲台。
全局内存(Global Memory):这是GPU中最大的内存,可以被所有线程跨所有线程块访问。然而,访问全局内存通常比其他内存类型慢,因此需要进行优化以避免性能下降。“学校模型”中的操场,学校有一个操场。
纹理内存和常量内存(Texture Memory and Constant Memory):这些是GPU中的特殊内存类型,针对访问特定数据类型(如纹理或常量值)进行了优化。所有线程跨所有线程块都可以访问这些内存类型。
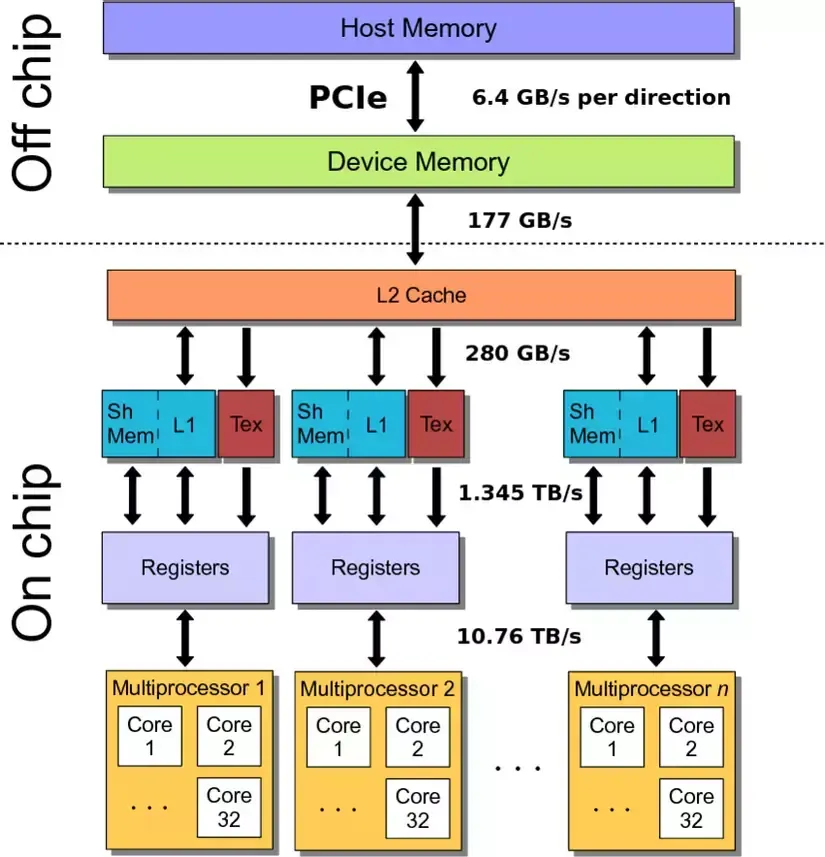
物理访存过程
不同的Memory之间的带宽有着显著的区别。CPU (host) and GPU (device)之间通过PCIe连接,速度最慢(Host2DeviceorDevice2Host,~32 GB/s)。
Device Memory(显存)其次。然后是L2 Cache、L1 Cache/Shared Memory,最快的是Registers。
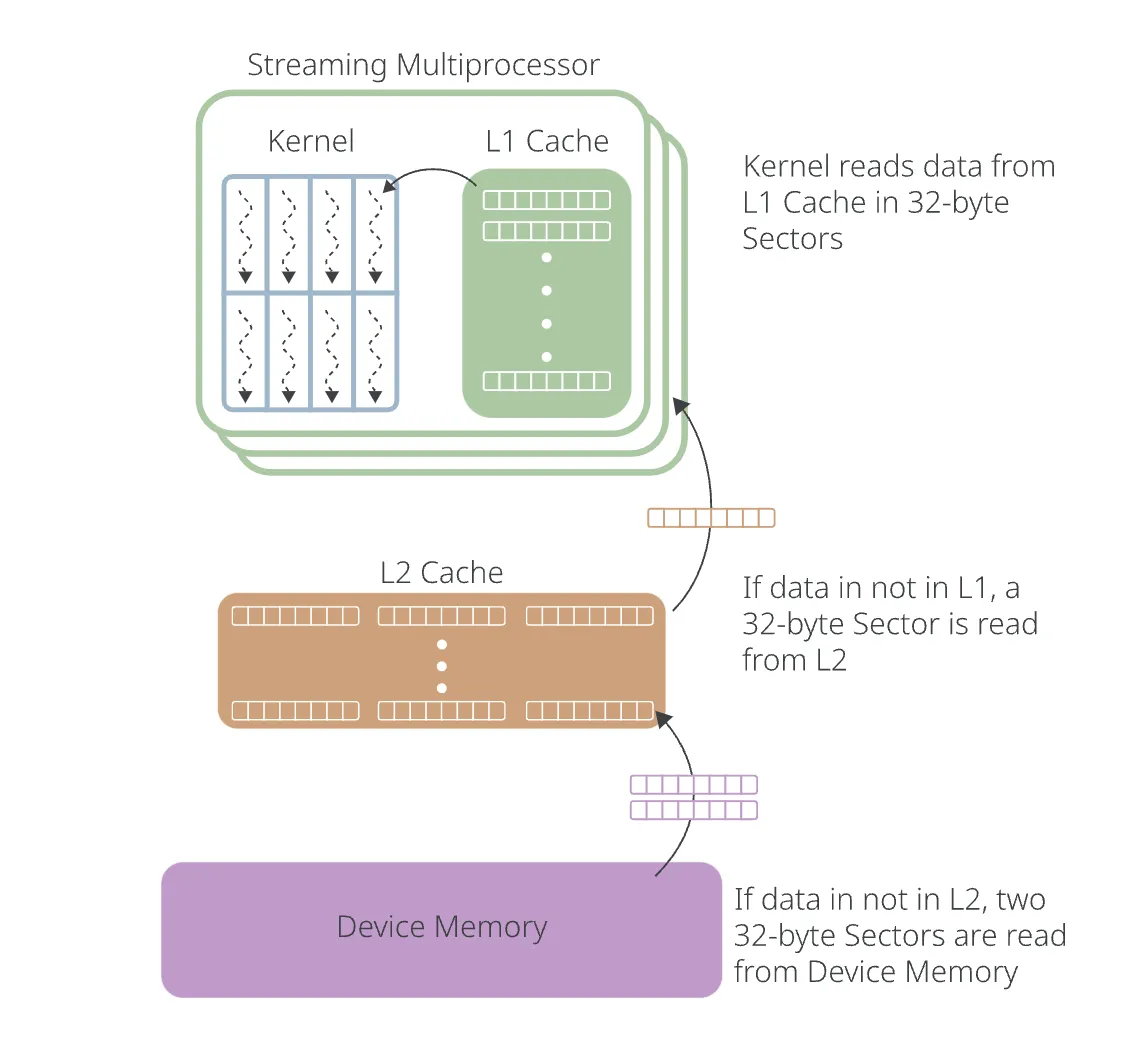
Global Memory
当某个CUDA kernel尝试访问Global Memory(Logical Memory Space)时,实际的的过程如下:
- 尝试从L1 Cache中查找,if hit then return;
- (If L1 Cache miss,存在latency penalty)尝试从L2 Cache中查找,if hit then return;
- (If L2 Cache miss,存在latency penalty)尝试从Device Memory(显存)查找。
Shared Memory
是一个较小的物理空间。可以被同一个Block中的所有Threads所共享。在物理空间上,Shared Memory与L1 Cache位于同一片上Memory。CUDA编程者甚至可以自由地分配L1 Cache与Shared Memory的比例。
cudaFuncSetAttribute(
my_kernel,
cudaFuncAttributePreferredSharedMemoryCarveout,
20 // Use 20% of combined L1/Shared Memory for Shared Memory
);
为了利用Shared Memory来加速访存,在CUDA编程中,使用__shared__关键字修饰的变量为Shared Memory。如果某个地址空间在多个线程中需要反复多次使用,使用Shared Memory可以显著提升访存效率。因为可以避免每次从Global Memory中读取(可能存在 cache missing 带来 latency penalty)。
Local Memory与Registers
在CUDA kernel中声明的标量(scalar-type)局部变量(int、float),默认都会存储在寄存器(Registers)中。
以Nvidia A100为例,每个Thread最多可以有255个Registers,超出该部分的局部变量(寄存器耗尽)或者是数组等动态大小的类型会被存储到Local Memory中,Local Memory与Glocal Memory同样,是一个包含多级缓存(L1 Cache -> L2 Cache -> Device Memory)的逻辑存储空间。
使用Nvidia Nsight Compute可以直观的看到CUDA代码到PTX汇编中局部变量的内存空间分配的过程:

Some Official Specs
| Graphics Card | NVIDIA GeForce RTX 2080 | NVIDIA GeForce RTX 3090 | NVIDIA GeForce RTX 4090 |
|---|---|---|---|
| GPU Architecture | NVIDIA Turing | NVIDIA Ampere | NVIDIA Ada Lovelace |
| SMs | 46 | 82 | 128 |
| CUDA Cores / SM | 64 | 128 | 192 |
| CUDA Cores / GPU | 2944 | 10496 | 24,576 |
| Tensor Cores / SM | 8 (2nd Gen) | 4 (3rd Gen) | 6 (3rd Gen) |
| Tensor Cores / GPU | 368 (2nd Gen) | 328 (3rd Gen) | 768 (3rd Gen) |
| RT Cores | 46 (1st Gen) | 82 (2nd Gen) | 128 (3rd Gen) |
| Memory Bandwidth | 448 GB/sec | 936 GB/sec | 1008 GB/sec |
| L1 Data Cache/Shared Memory | 4,416 KB | 10,496 KB | 16,384 KB |
| L2 Cache Size | 4096 KB | 6144 KB | 73,728 KB |
| Register File Size | 11,776 KB | 20,992 KB | 32,768 KB |
| TGP (Total Graphics Power) | 225W | 350W | 450W |
| Transistor Count | 13.6 Billion | 28.3 Billion | 76.3 Billion |
CUDA编程
Why CUDA?
CUDA In Large Language Models
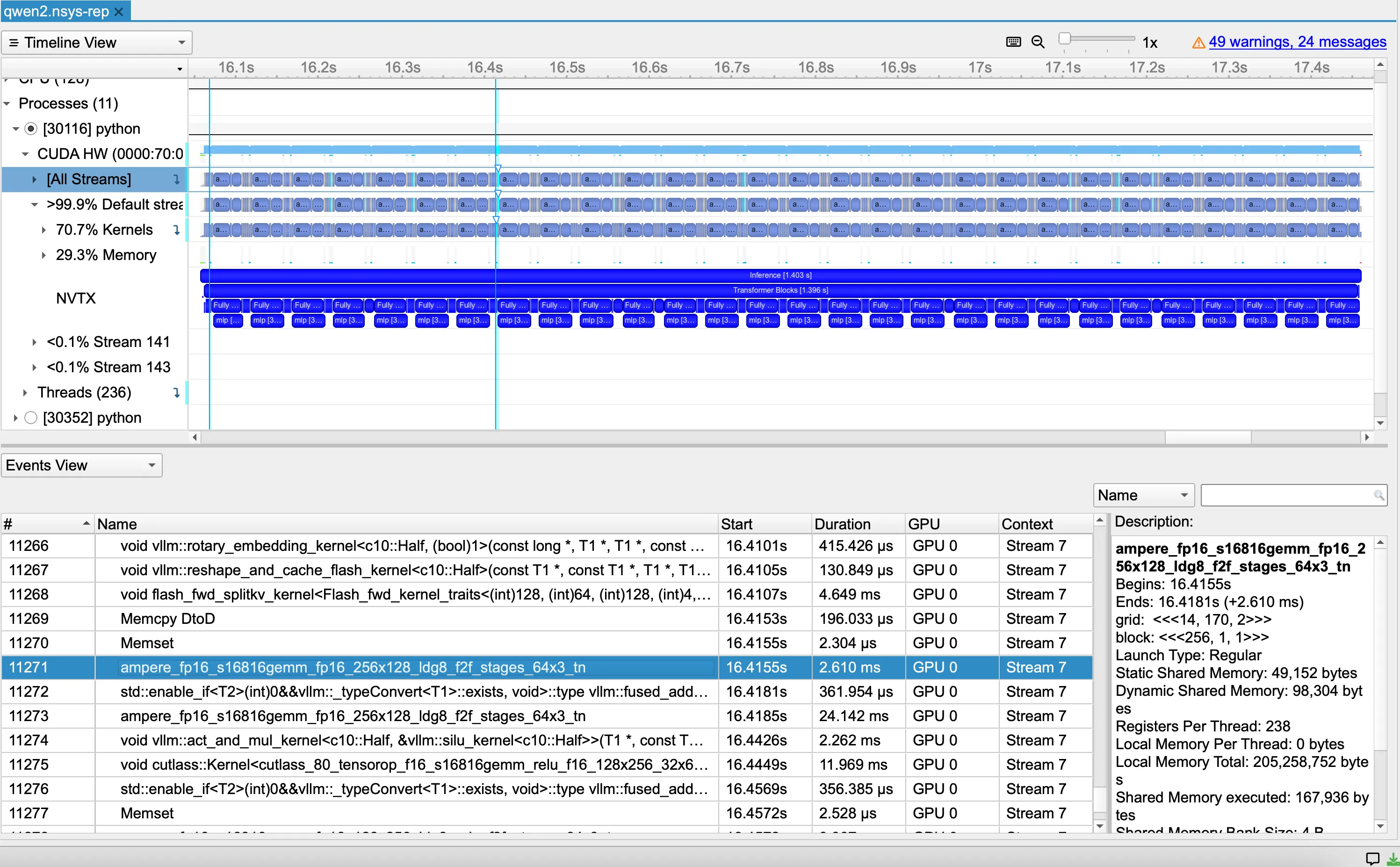
CUDA对于Generative AI的训练推理加速起着至关重要的作用,例如对于Qwen2的一次前向传播过程,虽然经过了Torch、 vLLM等框架的包装,但底层还是调用了CUDA来进行并行计算加速:
学习CUDA编程可以做什么?
- 针对特定场景的并行计算的加速,例如数字信号处理、视频编解码等领域;
- 特别的,For AI,可以手写CUDA kernel并集成到PyTorch、vLLM等框架中使用,以实现训练、推理加速等目的;
What is CUDA?
Nvidia GPU上的并行计算编程涉及到CPU与GPU之间的数据传输、处理、计算,支持C、C++等语言。
CUDA (Compute Unified Device Architecture)是Nvidia开发的一种并行计算开发框架,利用CUDA编程者可以利用GPU的硬件特性来进行并行计算的开发。
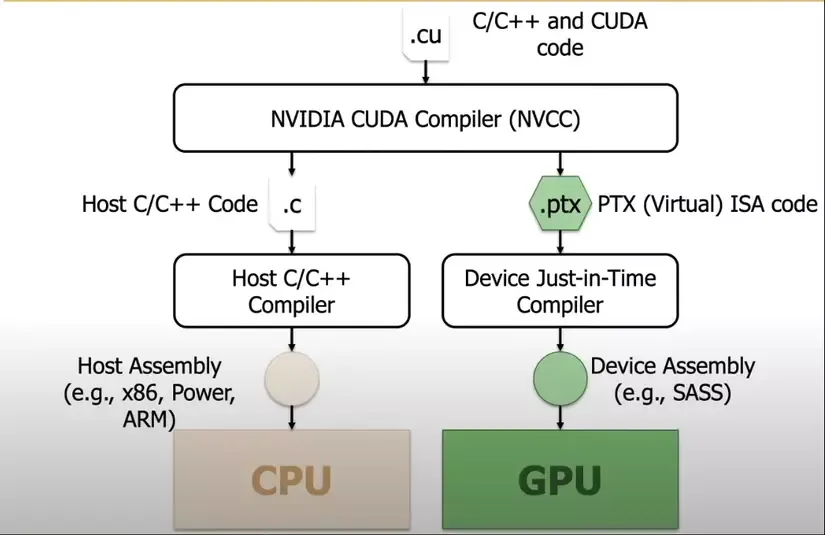
使用CUDA C/C++的文件的后缀为.cu,我们需要一个可以同时支持C/C++和CUDA的编译器。Nvidia开发了NVCC(NVIDIA CUDA Compiler),可以将C/C++和CUDA代码分别编译为在CPU以及GPU运行的二进制文件。NVCC的主要功能包括:
- 代码划分:区分.cu代码中哪些部分是CPU的代码,哪些部分是GPU的代码;
- 编译优化:Host代码(CPU)使用传统的C/C++编译器,而Device代码(GPU)使用CUDA编译器;
- 生成PTX:生成PTX代码 (PTX - Parallel Thread Execution),是一种运行在GPU上代码的中间表示;
- PTX翻译优化:将PTX代码翻译为GPU-specific machine code (SASS - Scalable Assembly) ,会根据硬件架构做专门的优化;
- Linking:将编译完成的CPU、GPU代码链接到一起生成最终的可执行二进制文件。
Hello World!
Getting Started
- 根据官网的教程安装
- 如果你的电脑没有Nvidia GPU,可以使用Google Colab,教程
确保CUDA被正确地添加到环境变量中,在终端中输入nvcc -V可以验证是否安装成功
Code Example
#include <stdio.h>
__global__ void kernel()
{
printf("hello world");
}
int main()
{
kernel<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}
__ host __: 调用和运行于CPU上的代码块,如果一个函数不含任何CUDA修饰符,则默认为host代码块,例如上面的main()函数。<span style="color:rgb(31, 35, 40);">int main()</span>与 <span style="color:rgb(31, 35, 40);">__host__ int main()</span>是等效的。
__device__:调用和运行于GPU上的代码块,
__ global __:被host代码块(CPU)调用,在device(GPU)上运行。
«<1,1»>: 调用kernel时需要指定的维度信息,第一个1表示Blocks的数量,第二个1表示每个Block中的Threads数量。用“学校模型”来理解,你作为校长,对于这个任务指定了一个班级,每个班级使用一个学生来处理。
cudaDeviceSynchronize():cuda device线程同步语句,可以确保GPU上的kernel线程全部执行完毕后,再运行后面的CPU代码。另外,在kernel内部,还有__syncthreads()可以确保同一个Block内的Threads完成同步。
Run Hello World!
将上面的代码保存为
- nvcc
.cu (-o )
然后运行生成的二进制可执行文件:
- ./a.out

Vector Add
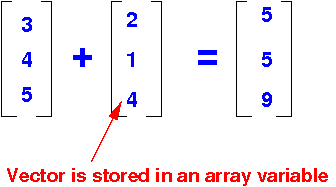
A CPU version of Vector Add
float *x, *y;
/* ==========================================
Allocate arrays to store vector x and y
========================================== */
x = calloc( N, sizeof(float) );
y = calloc( N, sizeof(float) );
/* ===============================================
CPU version of the vector addition algorithm
=============================================== */
for (i = 0; i < N; i++) // Add N elements...
y[i] = x[i] + y[i]; // Add one element at a time...
i=0
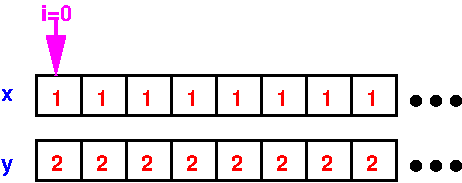
y[0] = x[0] + y[0]
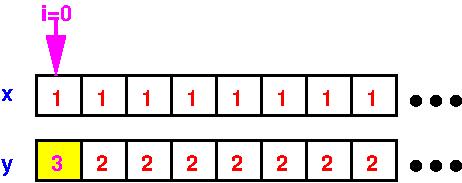
And so on….
Vector Add CUDA Kernel
// CUDA kernel to add two vectors
__global__ void vectorAdd(int *a, int *b, int *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
__global__ void定义了该函数是一个由CPU调用,GPU执行的CUDA kernel。
其中blockIdx.x * blockDim.x + threadIdx.x用于计算当前线程处理Vector中第几个元素的索引。
if (tid < N)保证了Vector的长度N不能被BLOCK_SIZE整除时,最后一个Block的线程不会访问越界;
About 1-D indexing:Why blockIdx.x * blockDim.x + threadIdx.x?
假设我们有4个Blocks,每个Block有8个Threads,来处理长度是32的Vector Add。那么Vector Index 21 位于第3个Block的第6个线程:

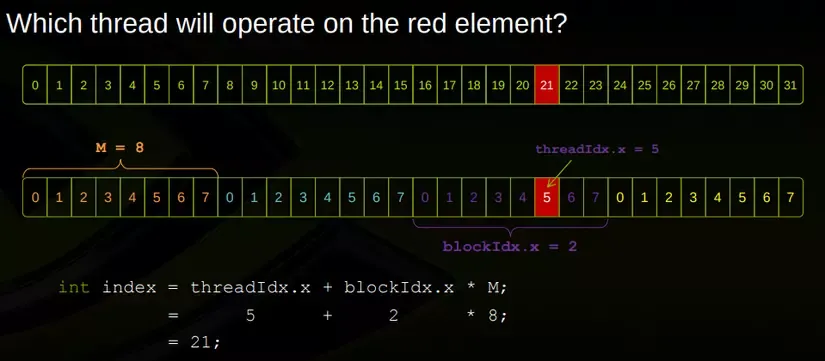
Vector Add Final Code
#include <stdio.h>
#include <stdlib.h>
// Size of the vector
#define N 32
#define BLOCK_SIZE 32
// CUDA kernel to add two vectors
__global__ void vectorAdd(int *a, int *b, int *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int *h_a, *h_b, *h_c; // Host vectors
int *d_a, *d_b, *d_c; // Device vectors
// Initialize host vectors
h_a = (int *)malloc(N * sizeof(int));
h_b = (int *)malloc(N * sizeof(int));
h_c = (int *)malloc(N * sizeof(int));
// Initialize host vectors with random values
for (int i = 0; i < N; i++) {
h_a[i] = rand() % 10;
h_b[i] = rand() % 10;
}
// Allocate device memory for vectors
cudaMalloc((void **)&d_a, N * sizeof(int));
cudaMalloc((void **)&d_b, N * sizeof(int));
cudaMalloc((void **)&d_c, N * sizeof(int));
// Copy data from CPU to GPU
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
// Call the CUDA kernel to perform vector addition
int numBlocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<numBlocks, BLOCK_SIZE>>>(d_a, d_b, d_c);
// Copy the result from GPU to CPU
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
// Print the result
for (int i = 0; i < N; i++) {
printf("h_a[%d] %d + h_b[%d] %d = %d\n", i, h_a[i], i, h_b[i], h_c[i]);
}
// Free memory
free(h_a);
free(h_b);
free(h_c);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
Initialization of values on the GPU
cudaMalloc: 为device申请内存空间,与C中的malloc类似。你阅读其他文档或者代码时,可能看到cudaMalloc((void **)&d_a, N * sizeof(int))或者cudaMalloc(&d_a, N * sizeof(int))两种写法,这两种写法是等效的;
cudaFree:为申请好的device空间进行内存释放,与C中的free类似;
cudaMemcpy:在host和device之间进行数据传输,分为cudaMemcpyHostToDevice(CPU主存到显存)和cudaMemcpyDeviceToHost(显存到CPU主存)两种方向;
关于kernel调用的部分:
// Call the CUDA kernel to perform vector addition
int numBlocks = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<numBlocks, BLOCK_SIZE>>>(d_a, d_b, d_c);
设BLOCK_SIZE为每个Block中的Threads数,那么可以用$ \lceil N / BLOCK_SIZE \rceil $来计算需要的Blocks数。(N + BLOCK_SIZE - 1) / BLOCK_SIZE实现了向上取整的除法。
Run Vector Add!

Run kernel with PyTorch
Install PyBind11
pip install "pybind11[global]"
我们使用pybind11来让我们的Cuda C/C++程序能够被链接到Python中使用。还是以向量相加为例,
我们现在希望写一个kernel,接受两个浮点类型的torch::Tensor,并返回他们相加的结果。
项目结构
project_root/
│
├── setup.py
│
└── csrc/
├── vector_add/
│ ├── vector_add_binding.cpp
│ └── vector_add.cu
vector_add.cu
之前我们之间使用main函数来调用CUDA kernel。而这次不同,我们使用了一个函数vector_add_launcher来调用CUDA kernel。该函数接受两个torch::Tensor类型作为输入,并返回他们的和。
- 首先,我们校验了a和b的维度,确保他们是一维向量。如果dim=2则为矩阵,dim=3则为三维张量。我们定义的kernel只进行一维向量的加法;
- 其次,校验了a和b的数据类型,确保他们是float32类型;
- 使用
torch::Tensor c = torch::empty_like(a);创建了返回值c,empty_like可以创建一个与a的形状、device等参数都相同,值未初始化的Tensor,用于保存结果; - 使用
vector_add<<<blocksPerGrid, BLOCK_SIZE>>>(a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N)调用CUDA kernel,其中a.data_ptr<float>()返回float类型的数组指针,指向Tensor的首个元素。
#include <torch/extension.h>
#define BLOCK_SIZE 256
__global__ void vector_add(const float* a, const float* b, float* c, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
c[i] = a[i] + b[i];
}
}
torch::Tensor vector_add_launcher(torch::Tensor& a, torch::Tensor& b) {
// Check the Tensor Dimension
if (a.dim() != 1 || b.dim() != 1) {
throw std::runtime_error("Input tensor must be one-dimensional");
}
// Check the Tensor Data Type
if (a.scalar_type() != torch::kFloat32 || b.scalar_type() != torch::kFloat32) {
throw std::runtime_error("Input tensor must be type of float32");
}
torch::Tensor c = torch::empty_like(a);
auto N = a.sizes()[0]; // array length
// Launch kernel
int blocksPerGrid = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vector_add<<<blocksPerGrid, BLOCK_SIZE>>>(a.data_ptr<float>(),
b.data_ptr<float>(), c.data_ptr<float>(), N);
return c;
}
vector_add_binding.cpp
然后我们创建一个 .cpp 文件vector_add_binding.cpp,其中包含了特殊的PYBIND11_MODULE声明,这样做可以允许我们使用Python代码来调用C++的代码。
#include <torch/extension.h>
torch::Tensor vector_add_launcher(torch::Tensor& a, torch::Tensor& b);
// Write the C++ function that we will call from Python
torch::Tensor vector_add_binding(torch::Tensor& a, torch::Tensor& b) {
return vector_add_launcher(a, b);
}
PYBIND11_MODULE(example_kernels, m) {
m.def(
"vector_add", // Name of the Python function to create
&vector_add_binding, // Corresponding C++ function to call
"Launches the vector_add kernel" // Docstring
);
}
对于C语言不熟悉的朋友,在这里特别解释一下,torch::Tensor vector_add_launcher(torch::Tensor& a, torch::Tensor& b);是函数的声明,编译完成后链接器会自动地在vector_add.cu中找到对应的函数实现。
在这里我们定义了函数vector_add_binding,这是Python代码调用C++函数的入口。在PYBIND11_MODULE中,我们定义了python模块example_kernels。并且定义了Python模块example_kernels的函数vector_add,对应于C++函数为vector_add_binding,并且可以在这里添加函数的说明。
setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
__version__ = "0.0.1"
# Define the C++ extension modules
ext_modules = [
CUDAExtension('example_kernels', [
'csrc/vector_add/vector_add_binding.cpp',
'csrc/vector_add/vector_add.cu',
]),
]
setup(
name="cuda_basics",
version=__version__,
ext_modules=ext_modules,
cmdclass={"build_ext": BuildExtension}
)
最后我们创建setup.py。利用Python的setuptools,这样每次我们在项目目录运行pip install .时,都会生成可以import的Python模块example_kernels。我们在项目目录下依次import torchimport example_kernels后测试一下。使用torch.tensor创建a、b两个一维的向量,指定类型为torch.float32,然后使用example_kernels.vector_add(a, b)调用我们的手写CUDA C++ kernel:
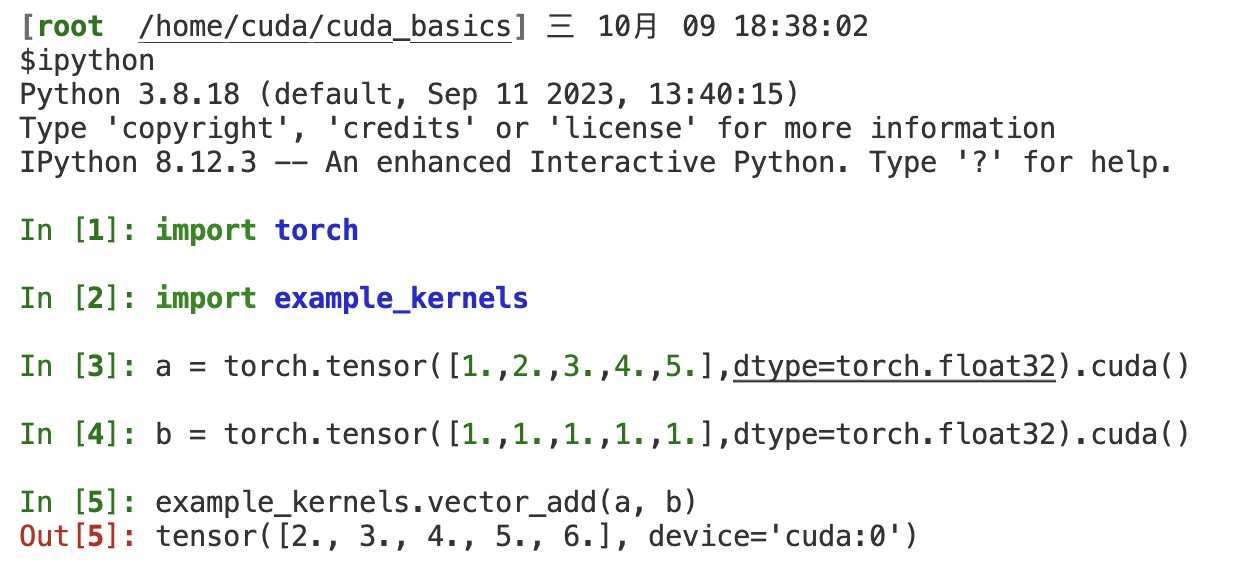
总结